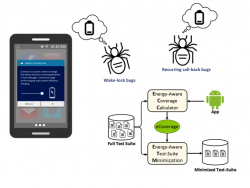
The utility of a smartphone is limited by its battery capacity and the ability of its hardware and software to efficiently use the device’s battery. To properly characterize the energy consumption of an app and identify energy defects, it is critical that apps are properly tested, i.e., analyzed dynamically to assess the app’s energy properties. However, currently there is a lack of testing tools for evaluating the energy properties of apps. We present COBWEB, a search-based energy testing technique for Android.
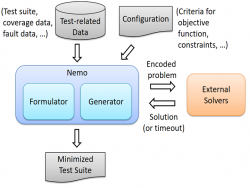
Multi-criteria test-suite minimization aims to remove redundant test cases from a test suite based on some criteria such as code coverage, while trying to optimally maintain the capability of the reduced suite based on other criteria such as fault-detection effectiveness. Existing techniques addressing this problem with integer linear programming claim to produce optimal solutions. However, the multi-criteria test-suite minimization problem is inherently nonlinear, due to the fact that test cases are often dependent on each other in terms of test-case criteria.
The rising popularity of mobile apps deployed on battery-constrained devices underlines the need for effectively evaluating their energy properties. However, currently there is a lack of testing tools for evaluating the energy properties of apps. As a result, for energy testing, developers are relying on tests intended for evaluating the functional correctness of apps. Such tests may not be adequate for revealing energy defects and inefficiencies in apps.
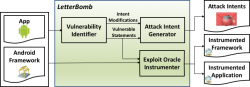
Although a wide variety of approaches identify vulnerabilities in Android apps, none attempt to determine exploitability of those vulnerabilities. Exploitability can aid in reducing false positives of vulnerability analysis, and can help engineers triage bugs. Specifically, one of the main attack vectors of Android apps is their inter-component communication (ICC) interface, where apps may receive messages called Intents.
Recent introduction of a dynamic permission model in Android, allowing the users to grant and revoke permissions a at the installation of an app, has made it much harder to properly test apps. Since an app's behavior may change depending on the granted permissions, it needs to be tested under a wide range of granted permission combinations.
I am aiding core developers of the Linux kernel to use mutation analysis to improve kernel systems testing methods, and to verify critical algorithms. I am also investigating the use of bounded model checking (CBMC) on Linux kernel. As an outcome of this project so far we have identified 3 bugs in the Linux kernel. I am also applying mutation analysis on sqlite3 to improve its testing.
The rising popularity of mobile apps deployed on battery-constrained devices has motivated the need for effective energy-aware testing techniques. Energy testing is generally more labor intensive and expensive than functional testing, as tests need to be executed in the deployment environment, specialized equipment needs to be used to collect energy measurements, etc. Currently, there is a dearth of automatic mobile testing techniques that consider energy as a program property of interest.
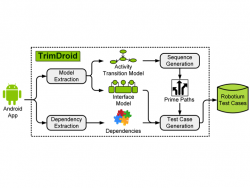
TrimDroid is a novel combinatorial approach for generating GUI system tests for Android apps.
TrimDroid is comprised of four major components: Model Extraction, Dependency Extraction, Sequence Generation, and Test-Case Generation. Together, these components produce a significantly smaller number of test cases than exhaustive combinatorial technique, yet achieve a comparable coverage.
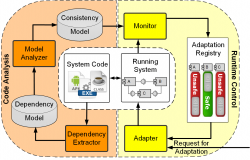
One of the most difficult tasks in debugging software for a developer is to understand the nature of the fault. Techniques have been proposed by researchers that can help *locate* the fault, but mostly neglected is a way to describe the nature of the fault. We are developing software models, visualizations, and techniques to aid in the diagnosis of the faults in the software.



 ISR
ISR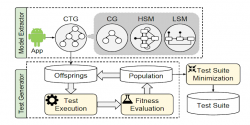
0ceb.png?itok=jT7i6DAQ)
6eb1.png?itok=WgWac6St)