

![]()

 ISR
ISR
Scaling Token-Based Code Clone Detection
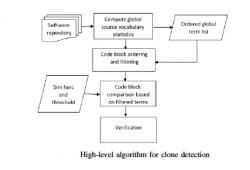
We developed a token-based approach for large scale code clone detection which is based on a filtering heuristic that reduces the number of token comparisons when the two code blocks are compared. We also developed a MapReduce based parallel algorithm that uses the filtering heuristic and scales to thousands of projects. The filtering heuristic is generic and can also be used in conjunction with other token-based approaches. In that context, we demonstrated how it can increase the retrieval speed and decrease the memory usage of the index-based approaches.
In our experiments on 36 open source Java projects, we found that: (i) filtering reduces token comparisons by a factor of 10, and thus increasing the speed of clone detection by a factor of 1.5; (ii) the speed-up and scale-up of the parallel approach using filtering is near-linear on a cluster of 2-32 nodes for 150-2800 projects; and (iii) filtering decreases the memory usage of index-based approach by half and the search time by a factor of 5.
This work was followed by SourcererCC: Scaling Type-3 Clone Detection to Large Software Repositories.