We are on the cusp of a major opportunity: software tools that take advantage of Big Code. Specifically, Big Code will enable novel tools in areas such as security enhancers, bug finders, and code synthesizers. What do researchers need from Big Code to make progress on their tools? Our answer is an infrastructure that consists of 100,000 executable Java programs together with a set of working tools and an environment for building new tools.
Previous studies have shown that there is a non-trivial amount of duplication in source code. We analyzed a corpus of 2.6 million non-fork projects hosted on GitHub representing over 258 million files written in Java, C++ Python and JavaScript. We found that this corpus has a mere 54 million unique files. In other words, 79% of the code on GitHub consists of clones of previously created files. There is considerable variation between language ecosystems. JavaScript has the highest rate of file duplication, only 7% of the files are distinct.
Spacetime is a framework for developing time-stepped, multi-worker applications based on the tuplespace model. Workers compute within spacetimed frames -- a fixed portion of the shared data during a fixed period of time. The locally modified data may be pushed back to the shared store at the end of each step.
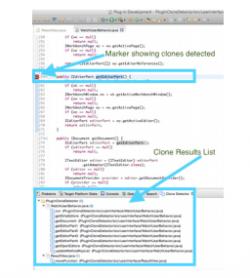
Given the availability of large-scale source-code repositories, there have been a large number of applications for clone detection. Unfortunately, despite a decade of active research, there is a marked lack in clone detectors that scale to large software repositories. In particular for detecting near-miss clones where significant editing activities may take place in the cloned code.
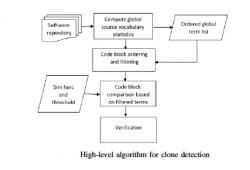
We developed a token-based approach for large scale code clone detection which is based on a filtering heuristic that reduces the number of token comparisons when the two code blocks are compared. We also developed a MapReduce based parallel algorithm that uses the filtering heuristic and scales to thousands of projects. The filtering heuristic is generic and can also be used in conjunction with other token-based approaches. In that context, we demonstrated how it can increase the retrieval speed and decrease the memory usage of the index-based approaches.
Sourcerer is an ongoing research project at the University of California, Irvine aimed at exploring open source projects through the use of code analysis. The existence of an extremely large body of open source code presents a tremendous opportunity for software engineering research. Not only do we leverage this code for our own research, but we provide the open source Sourcerer Infrastructure and curated datasets for other researchers to use.
The Sourcerer Infrastructure is composed of a number of layers.



 ISR
ISR