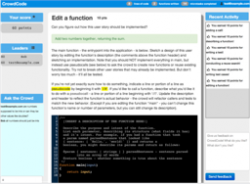
Microtask crowdsourcing systems such as FoldIt and ESP partition work into short, self-contained microtasks, reducing barriers to contribute, increasing parallelism, and reducing the time to complete work. Could this model be applied to software development? To explore this question, we are designing a development process and cloud-based IDE for crowd development.
The development of a software system is now ever more frequently a part of a larger development effort, including multiple software systems that co-exist in the same environment: a software ecosystem. Though most studies of the evolution of software have focused on a single software system, there is much that we can learn from the analysis of a set of interrelated systems. Topic modeling techniques show promise for mining the data stored in software repositories to understand the evolution of a system.
Anti-social behavior such as flaming and griefing is pervasive and problematic in many online venues. This behavior breaks established norms and unsettles the well-being and development of online communities. In a popular online game, Riot Games's League of Legends, the game company received tens of thousands of complaints about others every day. To regulate what they call "toxic" behavior, Riot devised the "Tribunal" system as a way of letting the community to police itself. The Tribunal is a crowdsoucing system that empowers players to identify and judge misbehavior.
One of the most difficult tasks in debugging software for a developer is to understand the nature of the fault. Techniques have been proposed by researchers that can help *locate* the fault, but mostly neglected is a way to describe the nature of the fault. We are developing software models, visualizations, and techniques to aid in the diagnosis of the faults in the software.
In addition to the dynamic nature of software while executing, this dynamism extends to the evolution of the software's code itself. The software's evolution is often captured in its entirety by revision-control systems (such as CVS, Subversion, and Git). By utilizing this rich artifact, as well as other historical artifacts (e.g., bug-tracking systems and mailing lists), we can offer a number of techniques for recommending future actions to developers.
In order to produce effective fault-localization, debugging, failure-clustering, and test-suite maintenance techniques, researchers would benefit from a deeper understanding of how faults (i.e., bugs) behave and interact with each other. Some faults, even if executed, may or may not propagate to the output, and even still may or may not influence the output in a way to cause failure. Furthermore, in the presence of multiple faults, faults may interact in a way to obscure each other or in a way to produce behavior not seen in their isolation.
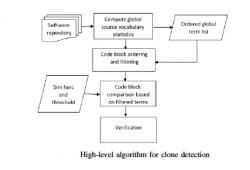
We developed a token-based approach for large scale code clone detection which is based on a filtering heuristic that reduces the number of token comparisons when the two code blocks are compared. We also developed a MapReduce based parallel algorithm that uses the filtering heuristic and scales to thousands of projects. The filtering heuristic is generic and can also be used in conjunction with other token-based approaches. In that context, we demonstrated how it can increase the retrieval speed and decrease the memory usage of the index-based approaches.
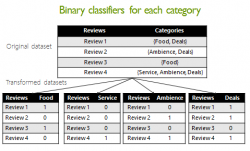
Yelp reviews and ratings are important source of information to make informed decisions about a venue. We conjecture that further classification of yelp reviews into relevant categories can help users to make an informed decision based on their personal preferences for categories. Moreover, this aspect is especially useful when users do not have time to read many reviews to infer the popularity of venues across these categories.



 ISR
ISR