![]()

 ISR
ISR
Microtasking Software Development
Crowdsourcing systems have demonstrated great success in enabling challenging tasks to be performed rapidly by massive crowds of casual workers. In 2011, players of the game Foldit were able to produce an accurate 3D model of an enzyme in just 10 days, a problem that had stumped researchers for 15 years. Over 10 million people use Duolingo to learn a language by translating small snippets of text. By aggregating these translations, Duolingo is able to rapidly produce translations of websites and other documents.
These crowdsourcing systems work by organizing work into microtasks. Microtasks enable work to be done rapidly by decomposing large tasks into smaller microtasks, enabling work to done in parallel. And by structuring work as short, self-contain tasks, many can quickly and easily contribute, increasing the potential pool of workers.
 There are many situations in which there is a clear need to build software rapidly: when responding to a disaster or fixing a suddenly apparent deficiency in a key software system. A common response is all hands on deck, mobilizing developers across an organization or community to work until the issue is resolved. But traditional development processes are not designed for this mobilization, making it challenging to support developers in making small contributions, identifying useful tasks, and coordinating the organized chaos of massive ad-hoc work.
There are many situations in which there is a clear need to build software rapidly: when responding to a disaster or fixing a suddenly apparent deficiency in a key software system. A common response is all hands on deck, mobilizing developers across an organization or community to work until the issue is resolved. But traditional development processes are not designed for this mobilization, making it challenging to support developers in making small contributions, identifying useful tasks, and coordinating the organized chaos of massive ad-hoc work.
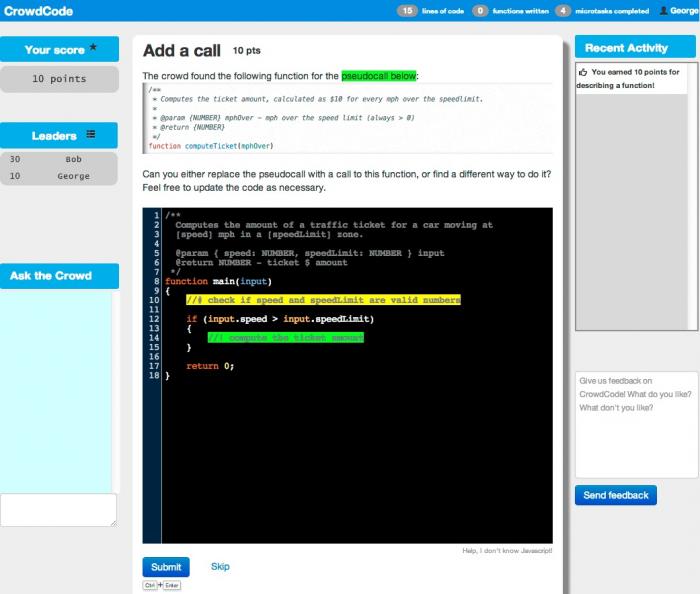
To address this need, ISR postdoctoral research associate Thomas LaToza, together with a team of students and ISR professor André van der Hoek, have been designing a development process for crowd development. In crowd development, workers are presented with short, self-contained microtasks of programming work. Each microtask provides a single artifact, such as a function, and asks the worker to perform a task, such as to write pseudocode or brainstorm test cases. For example, one worker might write a signature for function a, debug a test failure for b, and then edit the pseudocode the crowd wrote for a. To support this process, LaToza and his collaborators are designing CrowdCode, an IDE for software microtasks hosted in the cloud. CrowdCode tracks the state of each artifact, automatically generating microtasks as required. Workers login to CrowdCode, are given a microtask, and can immediately begin contributing.
Consider a simple example. Suppose the task is to calculate traffic tickets. The client first writes a user story: speeding tickets should be issued in the amount of $10 for every mph over the speed limit. To begin development, the system creates a microtask to write a main function and begin its implementation. As a worker begins this work, they might decide that the exact dollar amount of the speeding ticket should be computed in another function and write a pseudocall requesting a function to do this work. After finishing their work, they submit it to the server, which then fetches a new microtask to do next.
At this point, parallelism can begin. A microtask is created to begin enumerating test cases while, in parallel, another microtask is created to determine if a function exists with the functionality described by the pseudocall. As no such function yet exists, a microtask is spawned to write a description and signature for a new function providing the requested functionality. Next, microtasks can be spawned to implement the function, replace the pseudocall with a call to the new function, and implement each of the test cases.
Together with informatics Ph.D. student Christian Adriano, LaToza is currently investigating approaches for crowdsourcing debugging. One key challenge in crowdsourcing software development is to decompose tasks that traditionally require a global view of software into microtasks that are short and self-contained. Debugging tasks seem to inherently require a global view of the system, as the developer must localize the source of the bug to function(s) within the codebase. Yet, as a search process, there is also parallelism inherent in debugging: workers might investigate, in parallel, many potential locations of a bug.
As crowds of workers each change individual functions and tests in isolation, another challenge is integrating this work into a coherent whole. Working with informatics undergraduate Lucinda Lim, LaToza has explored an approach for support coordination across dependencies.As workers ask questions or change a function’s interface, a discussion thread is created, notifying dependent artifacts and allowing a discussion to occur.
Crowdsourcing systems achieve rapid work, in part, by soliciting contributions from large crowds, which may involve workers with widely divergent skills or even malicious workers. Thus, crowdsourcing also requires an approach to ensure the quality of the resulting software in the face of poor quality work. Together with informatics undergraduates Eric Chiquillo (now at Zynga) and Finlay Mitchell, LaToza has investigated approaches for reviews, reputation systems, and individualized incentives. Based on this work, Chiquillo won an Informatics department award for Outstanding Contribution to Research by an Undergraduate.
While still an ongoing research project, crowd development has already begun to generate interest, leading to an active collaboration with MobileWorks, a commercial crowdsourcing platform.
More broadly, crowdsourcing is beginning to generate increasing attention within the software engineering research community. Together with researchers at the University of Sheffield, the University of Milano, and Microsoft Research, LaToza is organizing a new workshop on Crowdsourcing in Software Engineering at the International Conference on Software Engineering (ICSE) in India in May 2014.